Agent Coverage Gap Dashboard
Overview
The Agent Coverage Gap Dashboard shows how well your agent is equipped to handle real customer topics — across both knowledge and instructions.
Coverage Insights includes:
- Knowledge Base (KB) Coverage – How well your KB content supports a topic.
- Prompt Coverage (New) – How clearly your agent prompt instructs the model to handle that topic.
- Deep Dive (New) – How the agent responded in real conversations, with surrounding context.
Coverage answers one core question:
When customers bring up this topic, does the agent have relevant guidance available?
The score reflects whether usable knowledge or instructions exist — not whether every response was perfect. Execution quality is validated separately through Deep Dive.
This allows QA teams to diagnose whether an issue stems from missing knowledge, unclear instructions, or behavioral execution.
Why Coverage Insights Matters
When a topic underperforms, the cause typically falls into one of three categories:
- Knowledge Gap – The KB lacks sufficient or relevant content.
- Instruction Gap – The prompt does not clearly define how to handle the topic.
- Execution Gap – Knowledge and instructions exist, but behavior in live conversations is weak.
Coverage Insights lets you quickly determine which layer needs improvement.
Summary Tiles
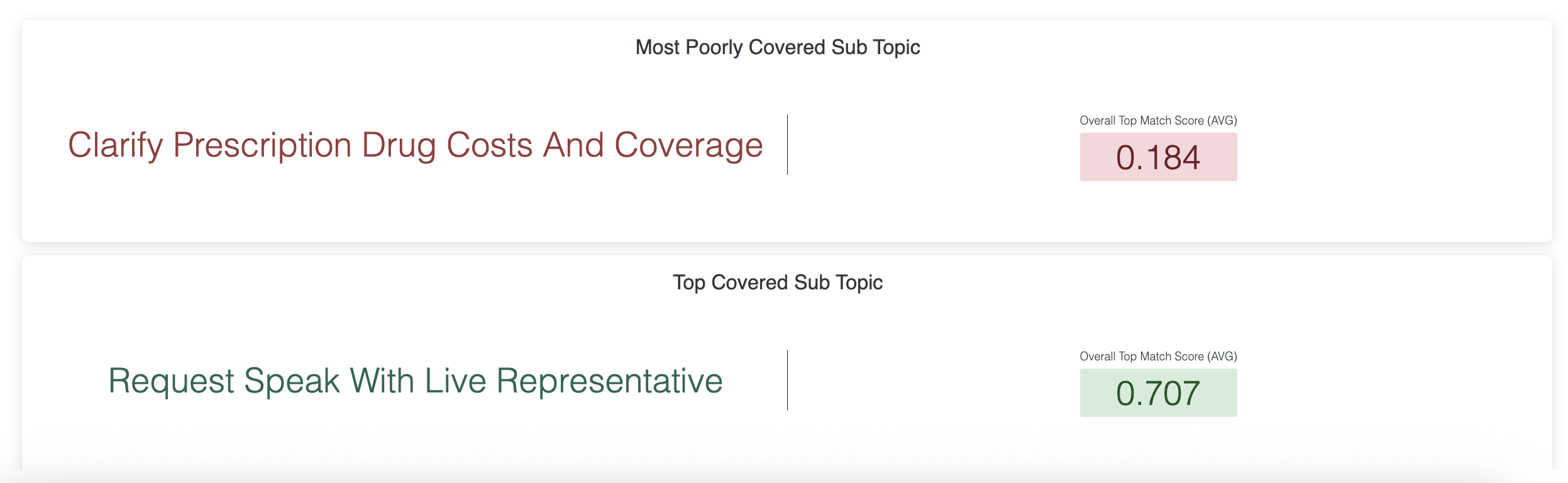
These tiles are the fastest “executive read” of where the agent is strongest vs. weakest. They’re also a helpful way to sanity-check whether the dashboard is looking at the kinds of topics you expect.
If the “worst-covered topic” is high volume or clearly business-critical, it’s often a strong candidate for your next improvement cycle.
Topic Table
The topic table is the core of the dashboard. Each row represents a recurring customer topic based on clustered customer moments, and the columns help you decide what to prioritize.
Here’s how to interpret the main signals in customer-operator terms:
Topic volume
This is shown through counts like the number of conversations and the number of customer utterances that fall into the topic. Volume answers: “How often does this show up?”
Overall coverage
This summarizes how well the topic is covered by any of the agent’s resources. A common way to read it is: “If a customer brings this up, does the agent have something relevant somewhere, knowledge or guidance?”
Knowledge base coverage
This isolates how well the topic matches the agent’s knowledge content. It’s especially relevant for factual questions, detailed policies, troubleshooting, and anything where the agent’s answer depends on accuracy and specificity.
Prompt coverage
This isolates how well the topic matches your prompt-level guidance, both Q&A guidance and workflow/task instructions. This is often the lever for improving: consistency, policy adherence, decision logic, and “what to do next” execution.
Talk time
This indicates the talk time for calls that had the given topic come up at some point. Depending on the Agent use case, a topic with longer talk time relative to others could indicate confusion, back-and-forth clarification, or a complex workflow. Talk time is most useful when paired with coverage: long talk time plus weak coverage usually signals a knowledge/instruction gap that is costing time.
Transfer rate
This indicates the percent of calls where the topic came up then eventually transferred. For a lot of Agent use cases transfer rate is often the clearest operational “pain” signal. If a topic shows both weak coverage and a high transfer rate, you’ve found a likely driver of escalations, something the agent repeatedly can’t fully resolve.
Negative sentiment
Negative sentiment helps you avoid optimizing purely for coverage scores. If a topic has decent coverage but still correlates with negative sentiment, the issue may be content quality, policy tone, workflow friction, or how the agent executes, not missing information.
How to Use KB Coverage Dashboard
Prioritization Model: Where to Focus?
Coverage should always be interpreted alongside topic volume.
Each topic includes:
- Count Recordings – Number of conversations where the topic appeared.
- Count Utterances – Number of distinct customer statements within the topic.
Use color + volume to prioritize:
- High volume + Yellow/Red → High-impact improvement opportunity.
- Green + poor outcomes → Likely instruction clarity or decision-rule issue.
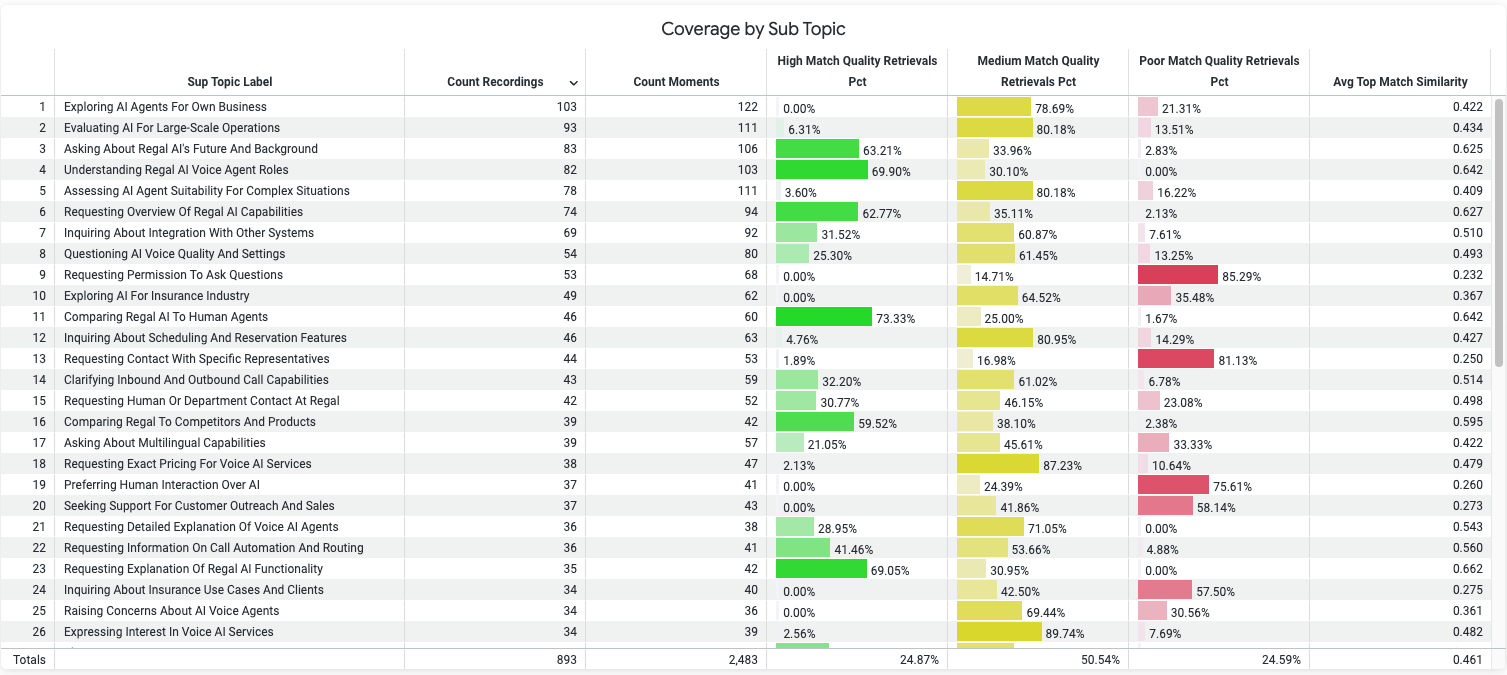
Understanding KB Coverage Metrics
The dashboard categorizes KB matches into High, Medium, or Poor quality, determined by a mathematical scoring model.
High-quality match: KB provided a clear, accurate, complete answer to the query.
Medium-quality match: KB partially addresses the request but lacks completeness or specificity.
Poor-quality match: KB fails to address the request, contains outdated or irrelevant info, or causes customer confusion.
Key points to note:
- Match quality is measured per subtopic.
- Review top subtopics by poor match percentage to prioritize fixes.
- High-frequency subtopics with poor matches represent high-impact improvement opportunities.
An important interpretation principle: coverage is most actionable when interpreted alongside operational friction. Depending on the Agent's goal, a low-coverage topic with minimal transfers and short talk time might be worth reviewing, but a low-coverage topic with high transfers is usually urgent.
Understanding Prompt Coverage (New)
Prompt Coverage evaluates whether the agent’s instructions clearly address how to handle the topic.
This includes:
- Q&A Instruction Text
- Task Steps Instruction Text
- State-based node instructions (for multi-state agents)
Prompt Coverage surfaces the most relevant instruction sections for the topic.
For multi-state agents, the surfaced node represents the most relevant instructional section — it does not guarantee the agent was in that state during the conversation.
Low Prompt Coverage signals that guidance may exist in documentation but is not explicitly defined in agent behavior.
Deep Dive (Updated)
Deep Dive allows you to review coverage at the individual customer moment level.
Each row represents a specific customer utterance within the selected topic and includes:
- Customer Utterance (enriched text)
- Context (surrounding snippet)
- Coverage Verdict (Well Covered / Partially Covered / Poorly Covered / No Sources)
- Best Coverage Source (KB / Q&A Prompt / Task Steps Prompt)
Use this view to validate root causes:
- No Sources / Poorly Covered → Add missing content or define escalation/transfer behavior.
- Partially Covered → Refine specificity, add examples, clarify decision rules.
- Repeated patterns across moments → High-priority update opportunity.
- Deep Dive confirms whether the issue is knowledge, instructions, or execution before changes are made.
Tip for Power Users:
Pair with Conversation Insights to see both topic performance (e.g. transfer rate, contact sentiment) and KB match quality for the same subtopics, ensuring you focus KB updates where they’re most needed.

QA Workflow Guide: Improving Agent Coverage
The best way to use the dashboard is as an operational improvement loop, repeatable, evidence-based, and tied to business outcomes.
Start with the topic table: identify your highest-leverage themes. Look first for topics that combine:
- Meaningfully high volume
- Lower overall coverage
- Differentiated talk time or transfer rate values
- Elevated negative sentiment
This step ensures you’re prioritizing topics that are both common and costly. Validate with row-level evidence before changing anything. Before you rewrite content or adjust guidance, drill into several example moments in the evidence view. You’re looking to answer:
- Are customers asking for something that truly isn’t covered?
- Is there existing content that should cover it, but isn’t matching well (too generic, too fragmented, or written in internal language)?
- Is the agent failing even when relevant information appears available (execution/workflow issue)?
Below is a practical example of using Coverage Insights to diagnose and fix a real issue.
Example Topic: “Pricing too high” vs competitor
Using the prioritization model (volume + coverage color), the team identifies:
- Topic: Pricing too high vs competitor
- High Count Recordings (frequent customer concern)
- Poor Best Overall Match Score (Red)
- Partial Prompt Coverage
- No meaningful KB Coverage
Initial observation:
The prompt contains general pricing objection handling, but the KB has no structured guidance on competitor comparisons or clear differentiation. There is nothing concrete for the agent to use when explaining why pricing differs.
Because the topic is high-volume and Red, it becomes a priority.
1. Validate in Deep Dive
The team filters for this topic and opens Deep Dive to review individual customer moments, relevant prompt sections, and KB sources.
They observe:
- Many moments marked Poorly Covered or No Sources.
- Generic agent responses such as “We offer competitive pricing” without differentiation.
- Subtle pricing hesitation not being recognized.
Examples of subtle phrasing include:
- “I’m just trying to see what makes this worth the jump.”
- “It feels like a bigger commitment than what I’m paying now.”
- “We’re already using something similar for less.”
These do not explicitly say “too expensive,” so existing Q&A logic does not always trigger.
Hypothesis:
The agent lacks both nuanced detection of pricing hesitation and grounded competitor differentiation content.
Tip: Topics dashboard is sorted by impact (highest volume x lowest score). Drill down, review agent response and recordings for a few utterances to form hypotheses.
2. Diagnose the Root Causes
Prompt Gap
- Q&A handles direct objections (“That’s too expensive”).
- It lacks examples of subtle pricing concerns.
- It does not clearly define when to shift into competitor comparison framing.
Knowledge Gap
- No KB article covering competitor comparisons.
- No structured explanation of differentiators.
- No approved positioning for “why we may cost more.”
Both instruction and content layers require updates.
3. Ship Concrete Updates
Prompt Update
The team enriches the Q&A section to:
Include examples of subtle pricing hesitation (“worth the jump,” “bigger commitment,” “using something similar for less”).
- Define when to move into differentiation framing.
- Provide structured handling:
- Acknowledge the concern.
- Clarify the current solution.
- Highlight 1–2 differentiators tied to business outcomes.
- Offer a next step (e.g., comparison walkthrough).
This improves detection and ensures consistent framing.
KB Update
The team adds and enriches KB content to include:
- A structured competitor comparison article.
- Clear feature and outcome differentiators.
- Guidance for explaining price differences.
- Approved language and common competitor name variants.
This ensures the agent has grounded, retrievable content to support comparison responses.
4. Monitor Weekly Improvement
Coverage reflects the latest prompt and KB configuration as new conversations are processed.
Each Monday, the team:
- Re-checks the Pricing vs Competitor topic.
- Reviews Best Overall Match Score, KB Coverage, and Prompt Coverage.
- Opens Deep Dive to confirm fewer “No Sources” moments and stronger differentiated responses.
If updates are effective, they should see:
- Coverage score improvement (Red → Yellow/Green).
- More “Well Covered” verdicts in Deep Dive.
- Clearer differentiation in transcripts.
- Downstream lift in transfer or conversion metrics.
A rising high-match percentage or improving sentiment score confirms the KB update is working.